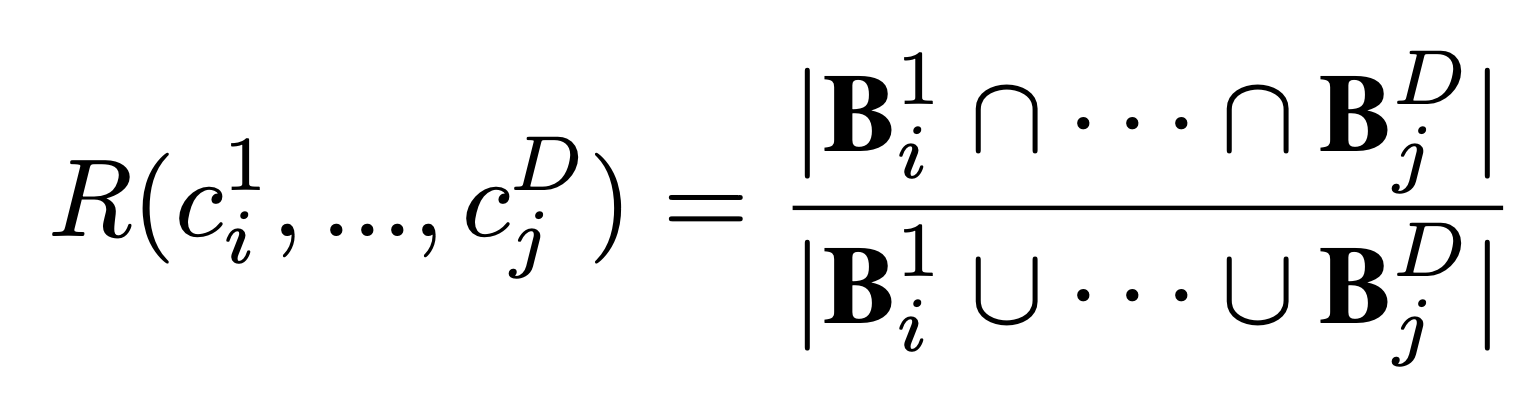What concepts are important for encoding object permanence in video transformers?
Input and Model Prediction
Layer 3 - Temporally Invariant Spatial Positions
Layer 7 - Collisions Between Objects
Layer 10 - Container Containing Object
Layer 12: Object Tracking Through Occlusions
VTCD discovers spatiotemporal concepts in video transformer models.
Abstract
This paper studies the problem of concept-based interpretability of transformer representations for videos.
Concretely, we seek to explain the decision-making process of video transformers based on high-level,
spatiotemporal concepts that are automatically discovered.
Prior research on concept-based interpretability has concentrated solely on image-level tasks.
Comparatively, video models deal with the added temporal dimension, increasing complexity and posing
challenges in identifying dynamic concepts over time.
In this work, we systematically address these challenges by introducing the first Video Transformer
Concept Discovery (VTCD) algorithm.
To this end, we propose an efficient approach for unsupervised identification of units of video
transformer representations - concepts, and ranking their importance to the output of a model.
The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and
object-centric representations in unstructured video models.
Performing this analysis jointly over a diverse set of supervised and self-supervised representations,
we discover that some of these mechanism are universal in video transformers.
Finally, we demonstrate that VTCD can be used to improve model performance for fine-grained tasks.
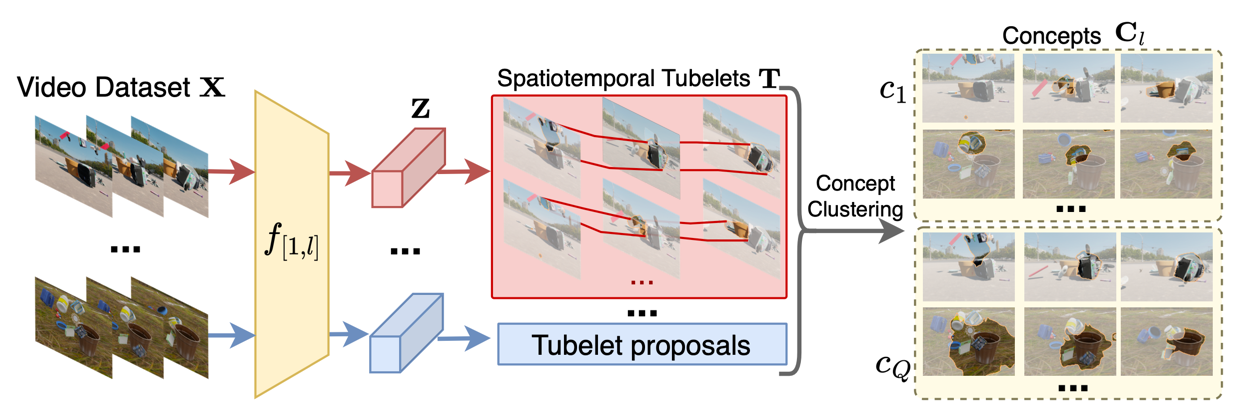
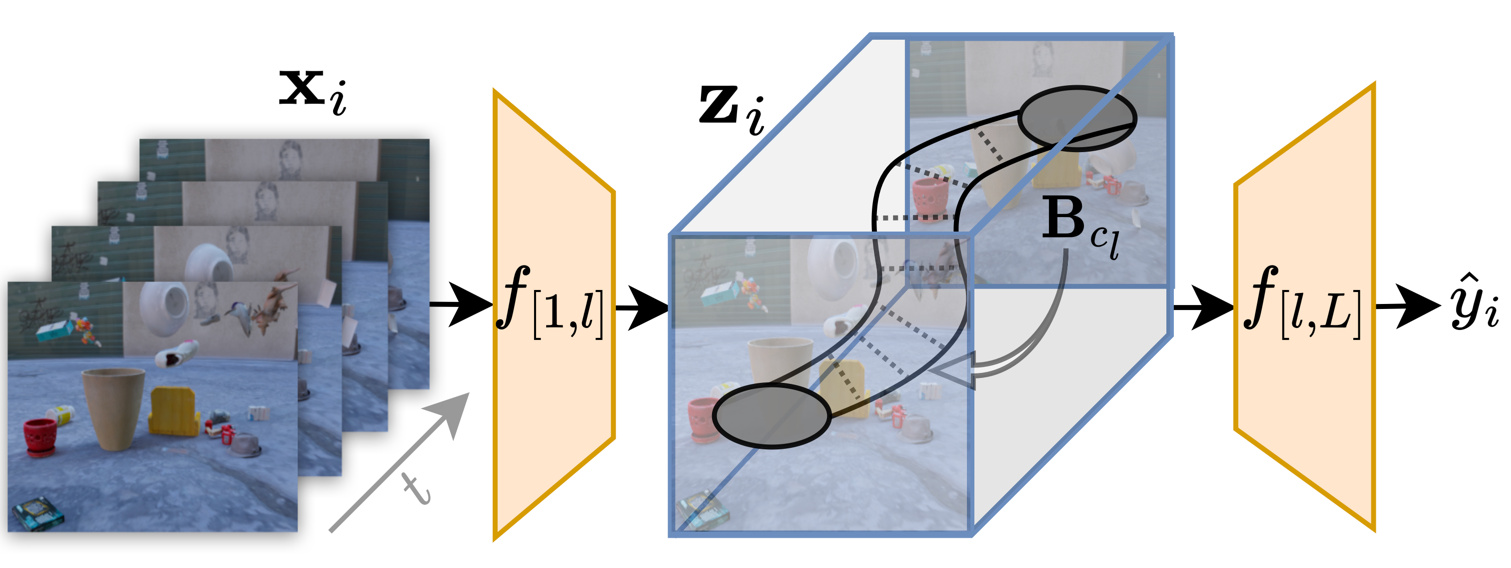
Method Overview
Concept Discovery
To discover concepts in video transformers, we first pass a video dataset through a pretrained model and extract
the activations of a given layer. We then cluster the activations using SLIC to generate spatiotemporal tubelets.
Finally, we cluster the dataset of tubelets and use the resulting centers as concepts.
Concept Importance
To rank the importance of concepts within individual transformer heads, we find that previous methods
based on gradients or masking out single concepts are not effective. Instead, we propose Concept
Randomized Importance Sampling (CRIS), which randomly samples concepts from the entire model to mask
out and measures the change in model performance.
Rosetta Concepts
In order to better understand fundamental computations performed by video transformers, we mine for
universal concepts across all models. We filter based on concept importance and on the Intersection
over Union (IoU) of the tubelets corresponding to each concept.
Results
We analyze four different models trained for different tasks: (i) TCOW trained for semi-supervised video
object segmentation to track objects through occlusions (ii) Supervised VideoMAE trained for action recognition (iii)
Self-supervised VideoMAE and (iv) InternVideo trained on video-text pairs via contrastive learning.
Most Important Concepts Discovered
Semi-supervised VOS Concepts - TCOW Concepts
Shown below are the most three important concepts discovered by VTCD for TCOW. We find that the most
important concept highlights objects with similar appearance, suggesting
the model solving the disambiguation problem by first identifying
possible distractors in mid-layers. The second concept highlights the
target object throughout the video. The third concept captures temporally invariant
spatial position in the top-left region of the video.
Concept 1 - Layer 5 Head 8
Concept 2 - Layer 9 Head 12
Concept 3 - Layer 3 Head 11
Action Recognition Concepts - VideoMAE Concepts
Shown below are the most three important concepts discovered by VTCD for VideoMAE trained on SSv2 targetting
the class `dropping something into
something'. The first concept highlights the object being dropped until the dropping event, at which point
both the object and container are highlighted. The second concept captures the container being dropped into,
notably not capturing the object itself and making a ring-like shape. As in the TCOW model, VideoMAE also
contains concepts that capture spatial information, this one highlighting the center of the video.
Concept 1 - Layer 5 Head 8
Concept 2 - Layer 9 Head 12
Concept 3 - Layer 3 Head 11
Rosetta Concepts
We now mine for Rosetta concepts across the models. Shown below are a sample of Rosetta concepts found
for the target SSv2 class `rolling something on a flat surface'. We find universal concepts across all models
capturing diverse information such as spatial position information and object centric concepts.
Spatial Positions
Input
TCOW Layer3
VidMAE Layer3
VidMAESSL Layer3
InternVideo Layer4
Input
TCOW Layer3
VidMAE Layer5
VidMAE-SSL Layer1
InternVideo Layer7
Object Tracking
Input
TCOW Layer9
VidMAE Layer11
VidMAE-SSL Layer12
InternVideo Layer10
Input
TCOW Layer4
VidMAE Layer8
VidMAE-SSL Layer10
InternVideo Layer10
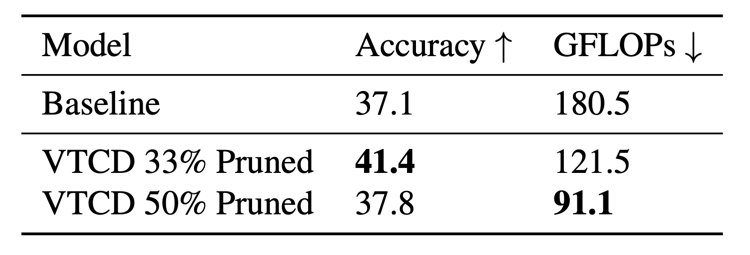
Application: Efficient Inference with Concept-Head Pruning
We propose a novel method for pruning transformer heads based on their importance. We target a
subset (6) of the classes in the SSv2 dataset and prune the least important heads based on CRIS.
We find that we can prune 30% of the heads to gain >4% in performance while reducing FLOPS, and
up to 50% of the heads without a significant drop in performance.
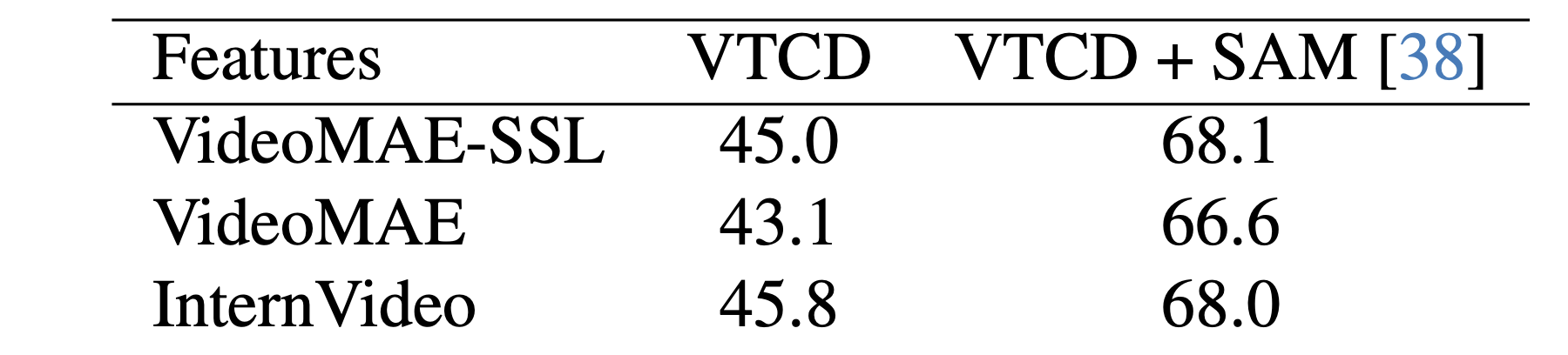
Application: Zero-Shot Semi-VOS with VTCD
We apply VTCD for the task of semi-supervised video object segmentation and evaluate the discovered concepts on the DAVIS’16
video-object segmentation benchmark. To this end, we run VTCD
on the training set and select concepts that have the highest
overlap with the groundtruth tracks. We then use them to
track new objects on the validation set. Not that are evaluating representations
that are not directly trained for VOS. While solid performance is achieved
by all representations, segmentation accuracy is limited by
the low resolution of the concept masks. To mitigate this,
we introduce a simple refinement step that samples random
points inside the masks to prompt Segment Anything Model (SAM). The resulting
approach, shown as ‘VTCD + SAM’, significantly improves
performance. We anticipate that future developments in
video representation learning will automatically lead to better VOS methods with the help of VTCD.
BibTeX
@article{kowal2024understanding,
author = {Kowal, Matthew and Dave, Achal and Ambrus, Rares and Gaidon, Adrien and Derpanis, Konstantinos G and Tokmakov, Pavel},
title = {Understanding Video Transformers via Universal Concept Discovery},
journal = {arXiv preprint arXiv:2401.10831},
year = {2024},
}