Matt Kowal

Mennatullah Siam

Md Amirul Islam

Neil D.B. Bruce

Richard P. Wildes

Konstantinos G. Derpanis
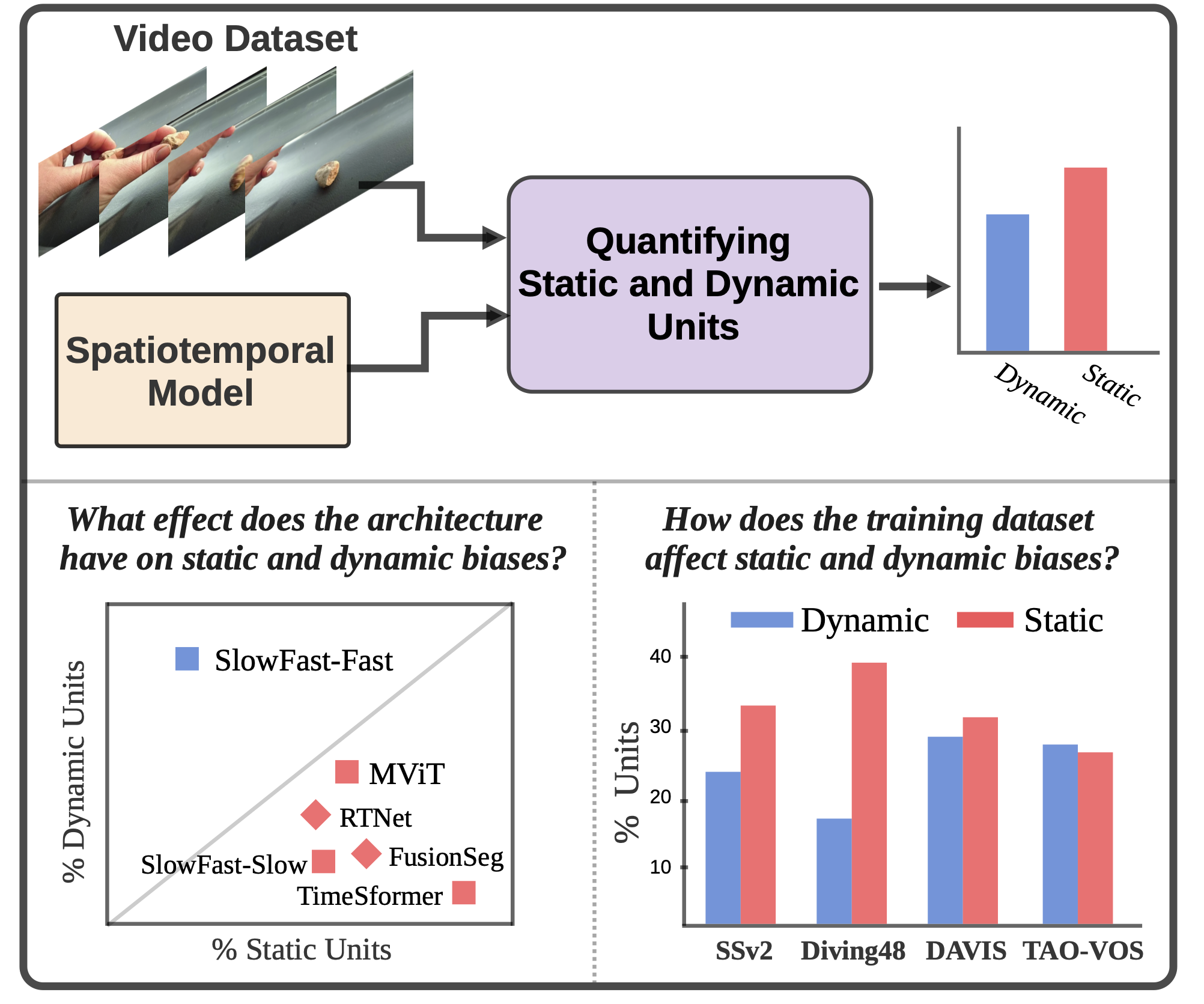
 We quantify the amount of static and dynamic information contained in spatio-temporal models through an estimation of mutual information between static and dynamic pairs. For action recognition models, the static pairs consist of the same video with shuffled frames. For the dynamic pair, we use the same video with two different styles. For video object segmentation (we explore two-stream models in this work), we use flow-jitter to perturb the dynamic information and stylization to perturb the static information.
We quantify the amount of static and dynamic information contained in spatio-temporal models through an estimation of mutual information between static and dynamic pairs. For action recognition models, the static pairs consist of the same video with shuffled frames. For the dynamic pair, we use the same video with two different styles. For video object segmentation (we explore two-stream models in this work), we use flow-jitter to perturb the dynamic information and stylization to perturb the static information.
 The first domain we study with our proposed approach is action recognition. A main finding in our work is that Diving48 is not as biased towards dynamics as previously thought. Interestingly, something-something-v2 guides the model to learn significantly more dynamic information than either Diving48 or Kinetics. Additionally, Diving48 results in `residual' neurons: neurons which encode neither static nor dynamic information.
The first domain we study with our proposed approach is action recognition. A main finding in our work is that Diving48 is not as biased towards dynamics as previously thought. Interestingly, something-something-v2 guides the model to learn significantly more dynamic information than either Diving48 or Kinetics. Additionally, Diving48 results in `residual' neurons: neurons which encode neither static nor dynamic information.
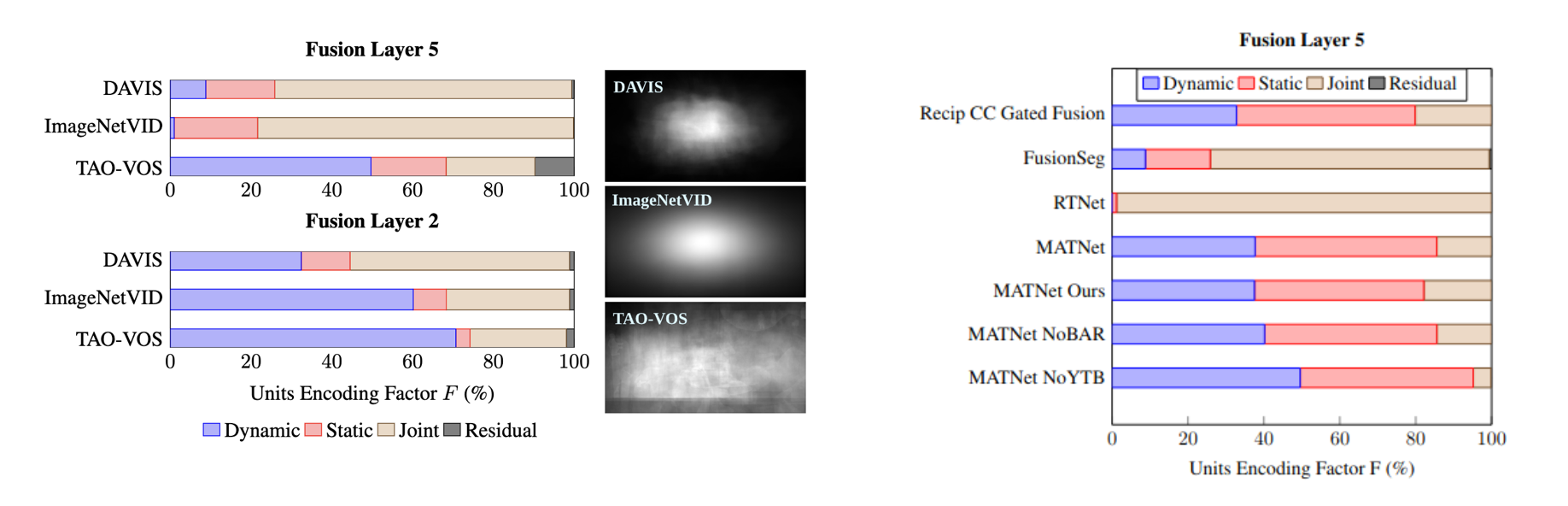 Our method has shown generality to other tasks such as video object segmentation (VOS). We found that 2-stream architectures with cross connections result in a better balance between static and dynamic. Originally, reciprocal (motion-to-appearance and appearance-to-motion) cross connections in RTNet showed few dynamic units. However, we showed that a model with reciprocal cross connections that does not undergo DUTS pretraining results in more dynamics. Finally, we show well known datasets used for training VOS models are static biased and find that TAOVOS may act as a better dataset to encourage the learning of dynamics.
Our method has shown generality to other tasks such as video object segmentation (VOS). We found that 2-stream architectures with cross connections result in a better balance between static and dynamic. Originally, reciprocal (motion-to-appearance and appearance-to-motion) cross connections in RTNet showed few dynamic units. However, we showed that a model with reciprocal cross connections that does not undergo DUTS pretraining results in more dynamics. Finally, we show well known datasets used for training VOS models are static biased and find that TAOVOS may act as a better dataset to encourage the learning of dynamics.
Matt Kowal
Mennatullah Siam
Md Amirul Islam
Neil D.B. Bruce
Richard P. Wildes
Konstantinos G. Derpanis